
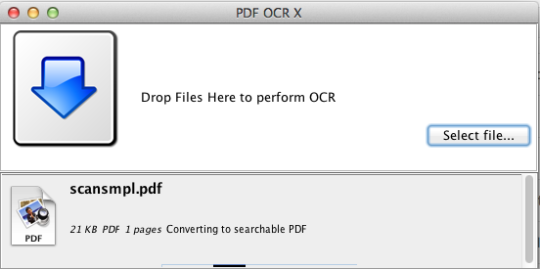
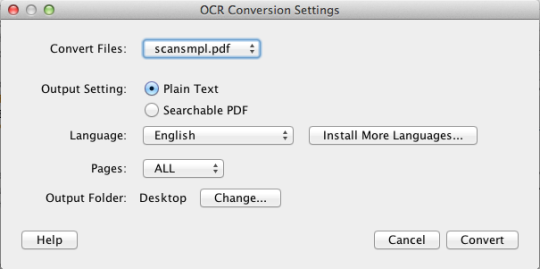
PDF OCR X یک ابزار کشیدن و رها کردن ساده برای Mac OS X است که فایل های PDF و تصاویر خود را به اسناد متنی و قابل جستجو PDF تبدیل می کند. این تکنولوژی پیشرفته OCR (تشخیص کاراکتر نوری) را برای استخراج متن PDF (یا تصویر) حتی اگر آن متن در یک تصویر وجود داشته باشد. این به خصوص برای برخورد با فایلهای PDF و تصاویری است که از طریق یک اسکن به PDF در اسکنر و یا کپی عکس ساخته شده است. پشتیبانی از بیش از 60 زبان برای OCR. موتور OCR مبتنی بر Tesseract است. نسخه اجتماعی یک صفحه PDF را پشتیبانی می کند (یا اولین صفحه چند فایل PDF).
نسخه 2.1.1 اضافه می کند پشتیبانی Mojave، و UI را بر روی صفحه نمایش شبکیه چشم را بهبود می بخشد.
در نسخه 2.0.8 جدید است:
مشکل ثابت با دست زدن برخی از فایل های PDF با چرخش.
محدودیت ها:
جامعه نسخه به PDF های یک صفحه و تصاویر محدود شده است.

نظر یافت نشد